
在資料分析時,很多時候我們都會想去除一些不感興趣的資料,這時我們可以用到filter() 這個函數,用起來也非常簡單,只要把判斷式放入即可,我們先將原始資料如先前的處理方式一樣,幫他加入Month 這個欄位。
result <- orders %>%
mutate(Month = as.Date(orders$CREATETIME, "%Y-%m-%d %H:%M:%S")) %>%
mutate(Month = substring(Month,1,7))
接著我們要找出營收最高的前三個月。
result <- orders %>%
mutate(Month = as.Date(orders$CREATETIME, "%Y-%m-%d %H:%M:%S")) %>%
mutate(Month = substring(Month,1,7)) %>%
group_by(Month) %>%
summarise(Income = sum(PRICE)) %>%
arrange(desc(Income))
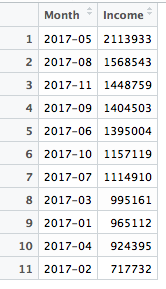
可以得到分別是五月、八月及十一月,接著就可以過濾資料啦。
result <- orders %>%
mutate(Month = as.Date(orders$CREATETIME, "%Y-%m-%d %H:%M:%S")) %>%
mutate(Month = substring(Month,1,7)) %>%
filter(Month=="2017-05"| Month=="2017-08"|Month=="2017-11",
PAYMENTTYPE=="信用卡") %>%
separate(NAME, c("Category", "Brand"), sep="\\(")
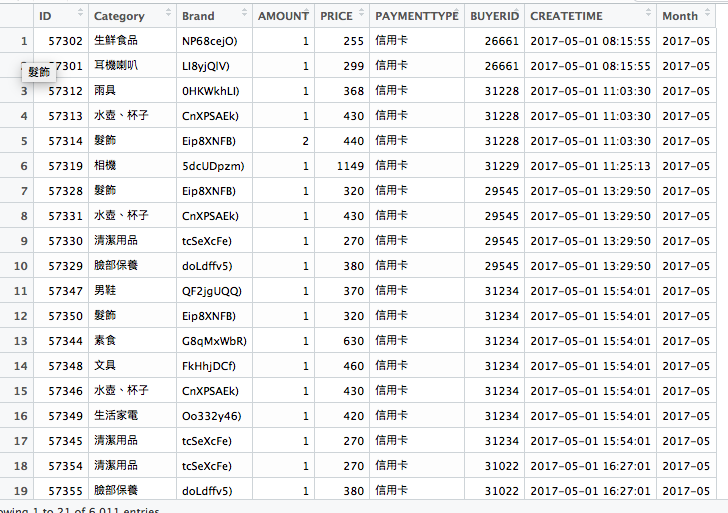
如上圖,看到付款方式都是信用卡,而且時間都是五月。
接著老樣子,根據種類排序即可得到我們要的結果了!
result <- orders %>%
mutate(Month = as.Date(orders$CREATETIME, "%Y-%m-%d %H:%M:%S")) %>%
mutate(Month = substring(Month,1,7)) %>%
filter(Month=="2017-05"| Month=="2017-08"|Month=="2017-11",
PAYMENTTYPE=="信用卡") %>%
separate(NAME, c("Category", "Brand"), sep="\\(") %>%
group_by(Category) %>%
summarise(Category_Income = sum(PRICE)) %>%
arrange(desc(Category_Income))
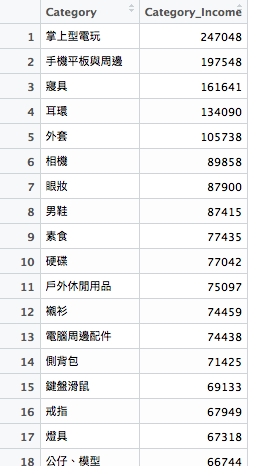
今天介紹的filter() 就是那麼簡單!
Ref
day7原始碼

